Dynamic Programming versus Memoization
posted by Shriram Krishnamurthi
[Edit on 2012–08–27, 12:31EDT: added code and pictures below. 2012–08–27, 13:10EDT: also incorporated some comments.]
I wrote this on the Racket educators’ mailing list, and Eli Barzilay suggested I post it here as well.
The article is about the difference between memoization and dynamic programming (DP). Before you read on, you should stop and ask yourself: Do I think these two are the same concept?; if you think they are different, How do I think they differ?; and for that matter, Do I even think of them as related?
Did you think? Okay, then read on.
They most certainly are related, because they are both mechanisms for optimizing a computation by replacing repeated sub-computations with the storage and reuse of the result of those sub-computations. (That is, both trade off space for time.) In that description is already implicit an assumption: that the sub-computation will return the same result every time (or else you can’t replace the computation with its value on subsequent invocations). You’ve almost certainly heard of DP from an algorithms class. You’ve probably heard of memoization if you’re a member of this language’s community, but many undergrads simply never see it because algorithms textbooks ignore it; and when they do mention it they demonstrate fundamental misunderstandings (as Algorithms by Dasgupta, Papadimitriou, and Vazirani does).
Therefore, let’s set aside precedent. I’ll tell you how to think about them.
Memoization is fundamentally a top-down computation and DP is fundamentally bottom-up. In memoization, we observe that a computational tree can actually be represented as a computational DAG (a directed acyclic graph: the single most underrated data structure in computer science); we then use a black-box to turn the tree into a DAG. But it allows the top-down description of the problem to remain unchanged. (As I left unstated originally but commenter23 below rightly intuited, the nodes are function calls, edges are call dependencies, and the arrows are directed from caller to callee. See the pictures later in this article.)
In DP, we make the same observation, but construct the DAG from the bottom-up. That means we have to rewrite the computation to express the delta from each computational tree/DAG node to its parents. We also need a means for addressing/naming those parents (which we did not need in the top-down case, since this was implicit in the recursive call stack). This leads to inventions like DP tables, but people often fail to understand why they exist: it’s primarily as a naming mechanism (and while we’re at it, why not make it efficient to find a named element, ergo arrays and matrices).
In both cases, there is the potential for space wastage. In memoization, it is very difficult to get rid of this waste (you could have custom, space-saving memoizers, as Vclav Pech points out in his comment below, but then the programmer risks using the wrong one…which to me destroys the beauty of memoization in the first place). In contrast, in DP it’s easier to save space because you can just look at the delta function to see how far “back” it reaches; beyond there lies garbage, and you can come up with a cleverer representation that stores just the relevant part (the “fringe”). Once you understand this, you realize that the classic textbook linear, iterative computation of the fibonacci is just an extreme example of DP, where the entire “table” has been reduced to two iteration variables. (Did your algorithms textbook tell you that?)
In my class, we work through some of the canonical DP algorithms as memoization problems instead, just so when students later encounter these as “DP problems” in algorithms classes, they (a) realize there is nothing canonical about this presentation, and (b) can be wise-asses about it.
There are many trade-offs between memoization and DP that should drive the choice of which one to use.
Memoization:
-
leaves computational description unchanged (black-box)
-
avoids unnecessary sub-computations (i.e., saves time, and some space with it)
-
hard to save space absent a strategy for what sub-computations to dispose of
-
must alway check whether a sub-computation has already been done before doing it (which incurs a small cost)
-
has a time complexity that depends on picking a smart computation name lookup strategy
In direct contrast, DP:
-
forces change in description of the algorithm, which may introduce errors and certainly introduces some maintenance overhead
-
cannot avoid unnecessary sub-computations (and may waste the space associated with storing those results)
-
can more easily save space by disposing of unnecessary sub-computation results
-
has no need to check whether a computation has been done before doing it—the computation is rewritten to ensure this isn’t necessary
-
has a space complexity that depends on picking a smart data storage strategy
[NB: Small edits to the above list thanks to an exchange with Prabhakar Ragde.]
I therefore tell my students: first write the computation and observe whether it fits the DAG pattern; if it does, use memoization. Only if the space proves to be a problem and a specialized memo strategy won’t help—or, even less likely, the cost of “has it already been computed” is also a problem—should you think about converting to DP. And when you do, do so in a methodical way, retaining structural similarity to the original. Every subsequent programmer who has to maintain your code will thank you.
I’ll end with a short quiz that I always pose to my class.
Memoization is an optimization of a top-down, depth-first computation for an answer. DP is an optimization of a bottom-up, breadth-first computation for an answer. We should naturally ask, what about
-
top-down, breadth-first
-
bottom-up, depth-first Where do they fit into the space of techniques for avoiding recomputation by trading off space for time?
-
Do we already have names for them? If so, what?, or
-
Have we been missing one or two important tricks?, or
-
Is there a reason we don’t have names for these?
Where’s the Code?
I’ve been criticized for not including code, which is a fair complaint. First, please see the comment number 4 below by simli. For another, let me contrast the two versions of computing Levenshtein distance. For the dynamic programming version, see Wikipedia, which provides pseudocode and memo tables as of this date (2012–08–27). Here’s the Racket version:
(define levenshtein (lambda (s t) (cond [(and (empty? s) (empty? t)) 0] [(empty? s) (length t)] [(empty? t) (length s)] [else (if (equal? (first s) (first t)) (levenshtein (rest s) (rest t)) (min (add1 (levenshtein (rest s) t)) (add1 (levenshtein s (rest t))) (add1 (levenshtein (rest s) (rest t)))))])))
The fact that this is not considered the more straightforward, reference implementation by the Wikipedia author is, I think, symptomatic of the lack of understanding that this post is about.
Now let’s memoize it (assuming a two-argument memoize):
(define levenshtein (memoize (lambda (s t) (cond [(and (empty? s) (empty? t)) 0] [(empty? s) (length t)] [(empty? t) (length s)] [else (if (equal? (first s) (first t)) (levenshtein (rest s) (rest t)) (min (add1 (levenshtein (rest s) t)) (add1 (levenshtein s (rest t))) (add1 (levenshtein (rest s) (rest t)))))]))))
All that changed is the insertion of the second line.
Bring on the Pitchers!
The easiest way to illustrate the tree-to-DAG conversion visually is via the Fibonacci computation. Here’s a picture of the computational tree:

Fibonacci tree
Now let’s see it with memoization. The calls are still the same, but the dashed ovals are the ones that don’t compute but whose values are instead looked up, and their emergent arrows show which computation’s value was returned by the memoizer.
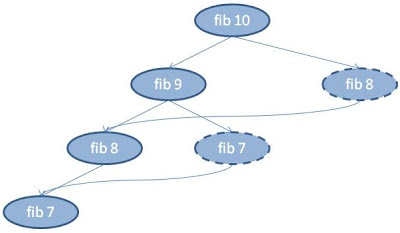
Fibonacci DAG
Important: The above example is misleading because it suggests that memoization linearizes the computation, which in general it does not. If you want to truly understand the process, I suggest hand-tracing the Levenshtein computation with memoization. And to truly understand the relationship to DP, compare that hand-traced Levenshtein computation with the DP version. (Hint: you can save some manual tracing effort by lightly instrumenting your memoizer to print inputs and outputs. Also, make the memo table a global variable so you can observe it grow.)