Dynamic Programming versus Memoization
posted by Shriram Krishnamurthi
[Edit on 2012–08–27, 12:31EDT: added code and pictures below. 2012–08–27, 13:10EDT: also incorporated some comments.]
I wrote this on the Racket educators’ mailing list, and Eli Barzilay suggested I post it here as well.
The article is about the difference between memoization and dynamic programming (DP). Before you read on, you should stop and ask yourself: Do I think these two are the same concept?; if you think they are different, How do I think they differ?; and for that matter, Do I even think of them as related?
Did you think? Okay, then read on.
They most certainly are related, because they are both mechanisms for optimizing a computation by replacing repeated sub-computations with the storage and reuse of the result of those sub-computations. (That is, both trade off space for time.) In that description is already implicit an assumption: that the sub-computation will return the same result every time (or else you can’t replace the computation with its value on subsequent invocations). You’ve almost certainly heard of DP from an algorithms class. You’ve probably heard of memoization if you’re a member of this language’s community, but many undergrads simply never see it because algorithms textbooks ignore it; and when they do mention it they demonstrate fundamental misunderstandings (as Algorithms by Dasgupta, Papadimitriou, and Vazirani does).
Therefore, let’s set aside precedent. I’ll tell you how to think about them.
Memoization is fundamentally a top-down computation and DP is fundamentally bottom-up. In memoization, we observe that a computational tree can actually be represented as a computational DAG (a directed acyclic graph: the single most underrated data structure in computer science); we then use a black-box to turn the tree into a DAG. But it allows the top-down description of the problem to remain unchanged. (As I left unstated originally but commenter23 below rightly intuited, the nodes are function calls, edges are call dependencies, and the arrows are directed from caller to callee. See the pictures later in this article.)
In DP, we make the same observation, but construct the DAG from the bottom-up. That means we have to rewrite the computation to express the delta from each computational tree/DAG node to its parents. We also need a means for addressing/naming those parents (which we did not need in the top-down case, since this was implicit in the recursive call stack). This leads to inventions like DP tables, but people often fail to understand why they exist: it’s primarily as a naming mechanism (and while we’re at it, why not make it efficient to find a named element, ergo arrays and matrices).
In both cases, there is the potential for space wastage. In memoization, it is very difficult to get rid of this waste (you could have custom, space-saving memoizers, as Vclav Pech points out in his comment below, but then the programmer risks using the wrong one…which to me destroys the beauty of memoization in the first place). In contrast, in DP it’s easier to save space because you can just look at the delta function to see how far “back” it reaches; beyond there lies garbage, and you can come up with a cleverer representation that stores just the relevant part (the “fringe”). Once you understand this, you realize that the classic textbook linear, iterative computation of the fibonacci is just an extreme example of DP, where the entire “table” has been reduced to two iteration variables. (Did your algorithms textbook tell you that?)
In my class, we work through some of the canonical DP algorithms as memoization problems instead, just so when students later encounter these as “DP problems” in algorithms classes, they (a) realize there is nothing canonical about this presentation, and (b) can be wise-asses about it.
There are many trade-offs between memoization and DP that should drive the choice of which one to use.
Memoization:
-
leaves computational description unchanged (black-box)
-
avoids unnecessary sub-computations (i.e., saves time, and some space with it)
-
hard to save space absent a strategy for what sub-computations to dispose of
-
must alway check whether a sub-computation has already been done before doing it (which incurs a small cost)
-
has a time complexity that depends on picking a smart computation name lookup strategy
In direct contrast, DP:
-
forces change in description of the algorithm, which may introduce errors and certainly introduces some maintenance overhead
-
cannot avoid unnecessary sub-computations (and may waste the space associated with storing those results)
-
can more easily save space by disposing of unnecessary sub-computation results
-
has no need to check whether a computation has been done before doing it—the computation is rewritten to ensure this isn’t necessary
-
has a space complexity that depends on picking a smart data storage strategy
[NB: Small edits to the above list thanks to an exchange with Prabhakar Ragde.]
I therefore tell my students: first write the computation and observe whether it fits the DAG pattern; if it does, use memoization. Only if the space proves to be a problem and a specialized memo strategy won’t help—or, even less likely, the cost of “has it already been computed” is also a problem—should you think about converting to DP. And when you do, do so in a methodical way, retaining structural similarity to the original. Every subsequent programmer who has to maintain your code will thank you.
I’ll end with a short quiz that I always pose to my class.
Memoization is an optimization of a top-down, depth-first computation for an answer. DP is an optimization of a bottom-up, breadth-first computation for an answer. We should naturally ask, what about
-
top-down, breadth-first
-
bottom-up, depth-first Where do they fit into the space of techniques for avoiding recomputation by trading off space for time?
-
Do we already have names for them? If so, what?, or
-
Have we been missing one or two important tricks?, or
-
Is there a reason we don’t have names for these?
Where’s the Code?
I’ve been criticized for not including code, which is a fair complaint. First, please see the comment number 4 below by simli. For another, let me contrast the two versions of computing Levenshtein distance. For the dynamic programming version, see Wikipedia, which provides pseudocode and memo tables as of this date (2012–08–27). Here’s the Racket version:
(define levenshtein (lambda (s t) (cond [(and (empty? s) (empty? t)) 0] [(empty? s) (length t)] [(empty? t) (length s)] [else (if (equal? (first s) (first t)) (levenshtein (rest s) (rest t)) (min (add1 (levenshtein (rest s) t)) (add1 (levenshtein s (rest t))) (add1 (levenshtein (rest s) (rest t)))))])))
The fact that this is not considered the more straightforward, reference implementation by the Wikipedia author is, I think, symptomatic of the lack of understanding that this post is about.
Now let’s memoize it (assuming a two-argument memoize):
(define levenshtein (memoize (lambda (s t) (cond [(and (empty? s) (empty? t)) 0] [(empty? s) (length t)] [(empty? t) (length s)] [else (if (equal? (first s) (first t)) (levenshtein (rest s) (rest t)) (min (add1 (levenshtein (rest s) t)) (add1 (levenshtein s (rest t))) (add1 (levenshtein (rest s) (rest t)))))]))))
All that changed is the insertion of the second line.
Bring on the Pitchers!
The easiest way to illustrate the tree-to-DAG conversion visually is via the Fibonacci computation. Here’s a picture of the computational tree:

Fibonacci tree
Now let’s see it with memoization. The calls are still the same, but the dashed ovals are the ones that don’t compute but whose values are instead looked up, and their emergent arrows show which computation’s value was returned by the memoizer.
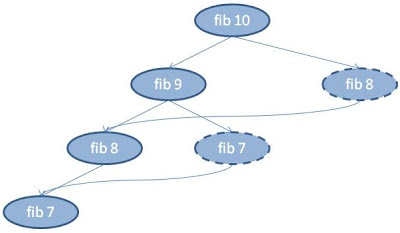
Fibonacci DAG
Important: The above example is misleading because it suggests that memoization linearizes the computation, which in general it does not. If you want to truly understand the process, I suggest hand-tracing the Levenshtein computation with memoization. And to truly understand the relationship to DP, compare that hand-traced Levenshtein computation with the DP version. (Hint: you can save some manual tracing effort by lightly instrumenting your memoizer to print inputs and outputs. Also, make the memo table a global variable so you can observe it grow.)
Nice teaser blog, but dry. Where is the code to explain such broad statements?
It sounds as if you have a point - Enough to make me want to see examples but there is nothing beneath to chew on.
— Paddy3118, 26 August 2012
Thank you for such a nice generalization of the concept. I elaborated on a specific task in one of my earlier posts (http://www.jroller.com/vaclav/entry/memoize_groovy_functions_with_gpars), where by simply adding memoization on top of a recursive Fibonacci function I end-up with linear time complexity. Since Groovy supports space-limited variants of memoize, getting down to constant space complexity (exactly two values) was easily achievable, too.
— Václav Pech, 26 August 2012
@Paddy3118: The simplest example I can think of is the Fibonacci sequence. The implementations in Javascript can be as follows. function FIB_MEMO(num) { var cache = { 1: 1, 2: 1 }; function innerFib(x) { if(cache[x]) { return cache[x]; } cache[x] = (innerFib(x–1) + innerFib(x–2)); return cache[x]; } return innerFib(num); } function FIB_DP(num) { var a = 1, b = 1, i = 3, tmp; while(i <= num) { tmp = a; a = b; b = tmp + b; i++; } return b; } It can be seen that the Memoization version “leaves computational description unchanged”. And the DP version “forces change in desription of the algorithm”. Also note that the Memoization version can take a lot of stack space if you try to call the function with a large number. The trade-offs mentioned at the end of the article can easily be seen in these implementations.
— simil, 26 August 2012
A small note from someone who was initially confused - it was hard to parse what you meant by converting a DAG into a tree as the article didn’t mention what the nodes and edges signify. Presumably the nodes are function calls and edges indicate one call needing another. And the direction of the arrows point from the caller to the callee? It would be more clear if this was mentioned before the DAG to tree statement. Nevertheless, a good article.
— commenter23, 26 August 2012
Inserting the line “memoize” may work beautifully, but it doesn’t really illuminate what’s going on. Would there be any point adding a version that expands that into explicitly checking and updating a table?
— sbloch, 27 August 2012
1) I completely agree that pedagogically it’s much better to teach memoization first before dynamic programming. The latter has two stumbling blocks for students: one the very idea of decomposing of a problem in terms of similar sub-problems, and the other the idea of filling up a table bottom-up, and it’s best to introduce them one-by-one. Then you can say “dynamic programming is doing the memoization bottom-up”. As an aside, for students who know mathematical induction, it sometimes helps them to say “dynamic programming is somewhat like induction”.
2) What are the fundamental misunderstandings in the Algorithms book? (I haven’t seen it.)
3) One issue with memoization that you didn’t mention is stack overflow. Because of its depth-first nature, solving a problem for N can result in a stack depth of nearly N (even worse for problems where answers are to be computed for multiple dimensions like (M,N)); this can be an issue when stack size is small.
— shreevatsa, 28 August 2012
Stephen (sbloch), sorry, but no time to do that right now. You’re right that that would help, but I was assuming the reader had some knowledge of memoization to begin with, or could look it up.
— Shriram Krishnamurthi, 29 August 2012
shreevatsa, +1 to everything you said.
I can’t locate the comment in Algorithms right now, but it was basically deprecating memoization by writing not particularly enlightened remarks about “recursion”.
One slight counter to your comment #2: if depth of recursion really is a problem, one could systematically eliminate it using techniques like CPS. Thus the solution can still be expressed as base functionality + functional abstractions + program transformations. This would be easier to read and to maintain.
— Shriram Krishnamurthi, 29 August 2012
Shriram and sbloch,
About to talk memoization to a class today. Here’s a Racket memoize that should work for any number of args on the memoized function:
(define (memoize f) (local ([define table (make-hash)]) (lambda args ;; Look up the arguments. ;; If they’re present, just give back the stored result. ;; If they’re not present, calculate and store the result. ;; Note that the calculation will not be expensive as long ;; as f uses this memoized version for its recursive call, ;; which is the natural way to write it! (dict-ref! table args (lambda () (apply f args))))))
— wolf, 19 September 2012
@wolf, nice, thanks. Keep in mind that different uses might want different kinds of equality comparisons (equal? vs eq?, say). May be good to remind your class of that. They could generalize your memoize to be parameterized over that (even in each position, if they want to go wild).
— Shriram Krishnamurthi, 19 September 2012
Got here from your parsing G+ post.
You are unfair towards Algorithms. The statement they make is: “However, the constant factor in this big-O notation is substantially larger because of the overhead of recursion.” That was true of hardware from more than 20 years ago; It’s not true today, as far as I know. Although you can make the case that with DP it’s easier to control cache locality, and cache locality still matters, a lot.
If you view these remarks as trying to say something about what memoization is, then they are wrong. But, they aren’t supposed to be remarks about what memoization is. They are simply practical considerations that are related to memoization.
Imagine someone says: “DFS might be more appropriate than BFS in this case, because space might be an issue; but be careful — most hardware takes a lot longer to execute a ‘call’ as compared to a ‘jmp’.” Is this statement a mis-informed indictment of DFS? Not really. You can do DFS without calls. For that matter, you can do memoization without ’call’s. (Oh, wait, you already mentioned CPS. :) )
— Radu Grigore, 2 December 2013
Radu, okay, my remark may be a bit too harsh. Sure. But I can throw in other criticisms too: the fact that it appears so late in the book, only as a sidebar, and is then called a “trick”, as if the DP version of the algorithm were somehow fundamental! Of course, the next criticism would be, “Hey, they at least mentioned it — most algorithms textbooks don’t do even that!” So at the end of the day, it’s all just damning with faint praise.
— Shriram Krishnamurthi, 2 December 2013
Also, Radu, I’m curious why it’s fine for a book written in 2006 to say things you believe were out of date for at least 13 years at that point. (-:
— Shriram Krishnamurthi, 2 December 2013
The statement they make about constant factors is about how hardware works, not about a fundamental issue. This is my point.
I’ll try to show you why your criticism is unfair, by temporarily putting you at the other end of a similar line of attack. So, please indulge me, and don’t get too annoyed.
— start —
Your omission of cache locality from the comparison demonstrates a fundamental misunderstanding. OK maybe that is a bit too harsh. However, it does show that you haven’t actually benchmarked your levenshtein implementation against a DP version that keeps only the fringe, so you don’t know what’s the difference in performance. But, how could anyone believe that not knowing this is OK?
— stop —
I believe that the above criticism of your post is unfair, and similar to your criticism of the book.
The book is a small jewel, with emphasis on small. It is packed with cool tricks (where “trick” is to be understood as something good). Too bad they wrote that book after I learned those tricks the tedious way.
Your post is pretty good too. I especially liked the quiz at the end.
— Radu Grigore, 3 December 2013
Shriram: I wasn’t sure whether they are right about the “overhead of recursion”. I thought they are wrong, but I did some experiments and it seems they are right-ish: http://rgrig.blogspot.com/2013/12/edit-distance-benchmarks.html
— Radu Grigore, 11 December 2013
Thanks. I did some experiments with using the same data structure in both cases, and I got a slight gain from the memoized version.
Note that my DP version uses an option type to prevent accidental use of an uninitialized slot, because if you truly want to compare the two, you should make sure you have the same safety characteristics.
Remove that and I believe the DP version is indeed a bit faster, but now you’re comparing a safe and unsafe implementation of a problem. That’s not a fair comparison and the difference can’t be attributed entirely to the calling mechanism.
Also, whether or not you use a “safe” DP, in the memoized version you also have to check for whether the problem has already been solved. How do you know that the overhead you’re seeing is entirely due to recursion, and not due to this?
— Shriram Krishnamurthi, 12 December 2013
I will have to disagree with what you call a fair comparison. But I want to use as a starting point a statement on which we probably agree: Memoization is more clear, more elegant, and safer.
But things like memoization and dynamic programming do not live in a totally ordered universe. There are multiple dimensions across which they can be compared, such as correctness and efficiency. Clarity, elegance and safety all have to do with correctness.
When you say that it isn’t fair to implement dp without options, that sounds to me like saying it isn’t fair to compare a program with an optimized version of itself. For example, like saying that comparing a program with array bounds checks against the version without bounds checks isn’t fair. And I can’t agree with this.
What wouldn’t be fair would be to not acknowledge that there is a trade-off involved: you gain efficiency, but you lose safety. The latter means that the programmer needs to do more work to achieve correctness. And yes, almost always this is a bad trade-off.
In summary, comparing memoization with a patched up version of dp that tries to recover some safety looks very odd to me.
“I believe the DP version is indeed a bit faster”
If by “a bit faster” you mean “about twice as fast”, then I agree. Otherwise, I’m tempted to ask to see your code. :)
“How do you know that the overhead you’re seeing is entirely due to recursion, and not due to [checking whether a result is already available]?”
I could add the checking overhead to dp and see how big it is. But why would I? The number you really care about when comparing efficiency is the overall time.
— Radu Grigore, 19 December 2013